Vous déployez Next.js sur votre propre infrastructure et vous avez remarqué que le cache en mémoire disparaît à chaque redémarrage ? Vous souhaitez partager le cache entre plusieurs instances ou simplement avoir plus de contrôle sur votre système de cache ? Ce guide complet vous explique comment créer et implémenter un cache handler personnalisé pour Next.js avec stockage persistant sur disque.
Dans cet article, nous allons couvrir :
- Les limitations du cache par défaut de Next.js en self-hosting
- L'architecture complète d'un cache handler personnalisé
- Une implémentation pas à pas avec code complet
- Des exemples pratiques basés sur un cas d'usage réel
- Les optimisations et bonnes pratiques
- La comparaison des différentes solutions (fichiers, Redis, S3)
- Le monitoring et le dépannage
Prêt à optimiser votre cache Next.js ? Commençons !
Comprendre le Cache Next.js : Pourquoi choisir un Handler Personnalisé ?
💡 Astuce : Si vous débutez avec Next.js, consultez d'abord la documentation officielle sur le cache pour comprendre les bases avant d'implémenter un handler personnalisé.
Le Cache par Défaut de Next.js
Par défaut, Next.js utilise un système de cache en mémoire basé sur l'algorithme LRU (Least Recently Used). Ce cache stocke directement les données en RAM et fonctionne très bien pour la plupart des cas d'usage, notamment sur des plateformes comme Vercel.
Caractéristiques du cache par défaut :
- ⚡ Très rapide : Accès direct à la mémoire RAM (< 1ms)
- 🔄 LRU automatique : Les entrées les moins utilisées sont supprimées automatiquement
- 📦 Intégré : Aucune configuration nécessaire
- ❌ Volatile : Perdu lors du redémarrage du serveur
- ❌ Non partagé : Chaque instance a son propre cache
- ❌ Limité par la RAM : Peut consommer beaucoup de mémoire
Limitations en Self-Hosting
Lorsque vous déployez Next.js sur votre propre infrastructure (VPS, Kubernetes, etc.), le cache en mémoire présente plusieurs limitations :
Perte au redémarrage : Après chaque redémarrage du serveur, le cache est perdu, ce qui entraîne un "cold start" complet
Pas de partage entre instances : Si vous scalez horizontalement avec plusieurs pods, chaque instance a son propre cache
Consommation RAM : Sur des serveurs avec peu de RAM, le cache peut être limité
Manque de visibilité : Difficile de voir ce qui est mis en cache et quand
Quand Utiliser un Cache Handler Personnalisé ?
Un cache handler personnalisé devient intéressant dans ces situations :
- Self-hosting : Vous déployez Next.js sur votre propre infrastructure (VPS, Kubernetes, Docker)
- Persistance requise : Vous voulez que le cache survive aux redémarrages du serveur
- Scaling horizontal : Vous avez plusieurs instances qui doivent partager le cache
- Contrôle et visibilité : Vous voulez inspecter et contrôler le cache (debugging, monitoring)
- Optimisation infrastructure : Vous voulez adapter le stockage à vos besoins (disque, Redis, S3)
⚠️ Important : Si vous utilisez Vercel ou une plateforme similaire, le cache par défaut est généralement suffisant et optimisé. Un cache handler personnalisé est principalement utile lorsque vous auto hébergé.
Comparaison : Cache en Mémoire vs Cache sur Disque
Vitesse
- Cache en Mémoire (défaut) : ⚡ Très rapide (< 1ms)
- Cache sur Disque (personnalisé) : 🐢 Plus lent (5-50ms)
Persistance
- Cache en Mémoire (défaut) : ❌ Perdu au redémarrage
- Cache sur Disque (personnalisé) : ✅ Persiste entre redémarrages
Partage
- Cache en Mémoire (défaut) : ❌ Par instance uniquement
- Cache sur Disque (personnalisé) : ✅ Partageable (volume, réseau)
- Kubernetes : Avec PVC partagé, automatiquement partagé entre tous les pods
- Docker Compose : Via volume nommé partagé
- VPS : Via volume réseau ou NFS
Limite
- Cache en Mémoire (défaut) : RAM disponible
- Cache sur Disque (personnalisé) : Espace disque disponible
Visibilité
- Cache en Mémoire (défaut) : ❌ Difficile à inspecter
- Cache sur Disque (personnalisé) : ✅ Fichiers visibles et inspectables
- Fichiers JSON dans .cache/
- Manifeste des tags consultable
- Commandes bash pour analyser
Complexité
- Cache en Mémoire (défaut) : ✅ Aucune configuration nécessaire
- Cache sur Disque (personnalisé) : ⚠️ Configuration requise
- Création du fichier cache-handler.mjs
- Configuration dans next.config.ts
- Gestion du nettoyage (optionnel)
Architecture du Cache Handler Personnalisé
Vue d'Ensemble du Système
Un cache handler personnalisé pour Next.js doit implémenter l'interface suivante :
interface CacheHandler {
get(key: string): Promise<{ value: any; lastModified: number } | null>;
set(key: string, data: any, ctx?: { tags?: string[] }): Promise<void>;
revalidateTag(tags: string | string[]): Promise<void>;
}
Flux de fonctionnement :
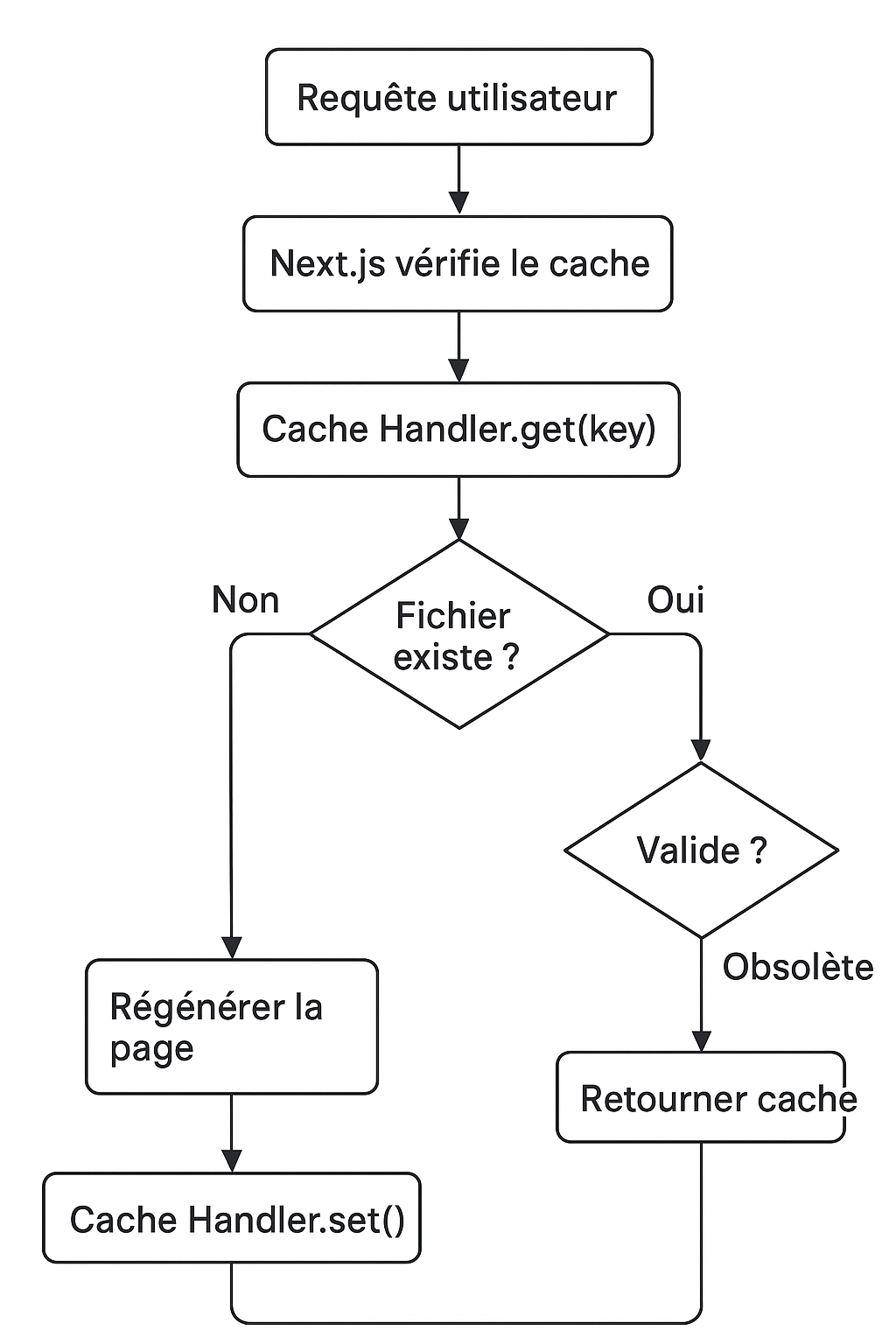
Structure de Stockage
Notre implémentation utilise le système de fichiers pour stocker les entrées de cache :
.cache/ ├── tags-manifest.json # Manifeste des tags et dates de revalidation
├── [encoded-key-1].json # Entrées de cache (clés encodées en URL)
├── [encoded-key-2].json └── ...
Structure d'une entrée de cache :
{
"value": {
"headers": { ... },
"body": "...",
"status": 200
},
"lastModified": 1704067200000,
"tags": ["/page-route", "custom-tag"]
}
Le fichier tags-manifest.json est au cœur du système de revalidation :
{
"items": {
"/page-route": {
"revalidatedAt": 1704067200000
},
"custom-tag": {
"revalidatedAt": 1704067300000
}
}
}
Fonctionnement :
Quand revalidateTag('custom-tag') est appelé, le timestamp est mis à jour
Lors d'un get(), on compare tagData.revalidatedAt avec entry.lastModified
Si revalidatedAt > lastModified, l'entrée est considérée comme obsolète
L'entrée obsolète est ignorée (retourne null)
Cela permet une revalidation en arrière-plan : la page continue d'être servie depuis le cache jusqu'à ce qu'une nouvelle version soit générée.
Implémentation Pas à Pas
Étape 1 : Configuration dans
La première étape consiste à configurer Next.js pour utiliser votre cache handler personnalisé :
import type { NextConfig } from 'next';
import path from 'path';
const nextConfig: NextConfig = {
cacheHandler: path.resolve('./cache-handler.mjs'),
cacheMaxMemorySize: 0,
};
export default nextConfig;
Points importants :
cacheHandler : Doit pointer vers un fichier .mjs (modules ES). Le chemin peut être absolu ou relatif à la racine du projetcacheMaxMemorySize: 0 : Désactive complètement le cache en mémoire. Sans cette valeur, Next.js utilisera les deux systèmes (mémoire + votre handler), ce qui peut causer des incohérences
🔍 Note technique : Next.js 13+ supporte les cache handlers personnalisés via l'option cacheHandler dans la configuration. Cette fonctionnalité est stable depuis Next.js 13.4.
Étape 2 : Création du Fichier
Créez le fichier cache-handler.mjs à la racine de votre projet :
import { promises as fs } from 'fs';
import path from 'path';
import pino from 'pino';
const logger = pino({
level: process.env.PINO_LOG_LEVEL || 'info',
formatters: {
level: (label) => {
return { level: label.toUpperCase() };
},
},
});
const CACHE_DIR = path.resolve('.cache');
const TAGS_MANIFEST = path.join(CACHE_DIR, 'tags-manifest.json');
const EXCLUDED_ROUTES = ['/robots.txt', '/sitemap.xml', '/sitemaps/'];
function isExcludedRoute(key) {
return EXCLUDED_ROUTES.some((route) => key.includes(route));
}
async function loadTagsManifest() {
try {
const data = await fs.readFile(TAGS_MANIFEST, 'utf8');
return JSON.parse(data);
} catch (err) {
if (err.code === 'ENOENT') {
return { items: {} };
}
throw err;
}
}
async function updateTagsManifest(tag, revalidatedAt) {
const manifest = await loadTagsManifest();
manifest.items[tag] = { revalidatedAt };
await fs.writeFile(TAGS_MANIFEST, JSON.stringify(manifest));
}
(async () => {
try {
await fs.mkdir(CACHE_DIR, { recursive: true });
logger.debug({ message: '🔧 Cache directory initialized' });
} catch (err) {
logger.error({
message: 'Failed to initialize cache directory',
error: err,
});
}
})();
class CacheHandler {
constructor() {
this.cacheDir = CACHE_DIR;
}
getFilePath(key) {
const sanitizedKey = key.trim();
const fileName = encodeURIComponent(sanitizedKey);
return path.join(this.cacheDir, fileName);
}
async get(key) {
if (isExcludedRoute(key)) {
logger.debug({ message: '🚫 Route exclue du cache', key });
return null;
}
const filePath = this.getFilePath(key);
try {
const data = await fs.readFile(filePath, 'utf8');
const entry = JSON.parse(data);
const { value, lastModified } = entry;
let cacheTags = entry.tags;
if (
(!cacheTags || cacheTags.length === 0) &&
value.headers &&
value.headers['x-next-cache-tags']
) {
cacheTags = value.headers['x-next-cache-tags'].split(',');
}
const tagsManifest = await loadTagsManifest();
let isStale = false;
for (const tag of cacheTags || []) {
const tagData = tagsManifest.items[tag];
if (tagData && tagData.revalidatedAt > lastModified) {
isStale = true;
logger.debug({
message: '♻️ Cache entry is stale due to tag revalidation',
key,
tag,
});
break;
}
}
if (isStale) {
return null;
}
logger.debug({ message: '✅ Cache hit', key });
return { lastModified, value };
} catch (_err) {
logger.debug({ message: '⚠️ Cache miss', key });
return null;
}
}
async set(key, data, ctx = {}) {
if (isExcludedRoute(key)) {
logger.debug({ message: '🚫 Route exclue du cache (set)', key });
return;
}
let tags = ctx.tags || [];
if (data && data.headers && data.headers['x-next-cache-tags']) {
const headerTags = data.headers['x-next-cache-tags'].split(',');
tags = [...new Set([...tags, ...headerTags])];
}
const entry = {
value: data,
lastModified: Date.now(),
tags,
};
const filePath = this.getFilePath(key);
try {
await fs.writeFile(filePath, JSON.stringify(entry));
logger.debug({ message: '📥 Set cached data', key, tags });
} catch (err) {
logger.error({
message: 'Failed to write cache entry',
key,
error: err,
});
}
}
async revalidateTag(tags) {
const tagsArray = Array.isArray(tags) ? tags : [tags];
logger.debug({
message: '🔄 Revalidating tags',
tags: tagsArray.join(', '),
});
const now = Date.now();
for (const tag of tagsArray) {
await updateTagsManifest(tag, now);
logger.debug({
message: '⏰ Tag revalidated',
tag,
revalidatedAt: new Date(now).toISOString(),
});
}
logger.debug({
message: '✨ Revalidation complete',
tags: tagsArray.join(', '),
});
}
}
export default CacheHandler;
Étape 3 : Installation des Dépendances
Assurez-vous d'avoir pino installé pour le logging :
npm install pino
pnpm add pino
yarn add pino
Étape 4 : Configuration des Variables d'Environnement
Ajoutez la variable pour contrôler le niveau de log :
PINO_LOG_LEVEL=debug
Exemples Pratiques : Cas d'Usage Réel
Exemple 1 : Page ISR avec Revalidation
Voici comment utiliser le cache handler avec une page ISR (Incremental Static Regeneration) :
import { fetchDetailAnnonce } from '@/features/annonce/detail/api/fetch-annonce';
export const revalidate = 21600;
export default async function PageAnnonce({ params }: Props) {
const { reference, localisation, locale } = await params;
const annonce = await fetchDetailAnnonce(reference, localisation, locale);
return (
<div> <h1>{annonce.titre}</h1> {/* Contenu de la page */} </div>
);
}
Fonctionnement :
La première requête génère la page et la met en cache
Les requêtes suivantes servent la page depuis le cache
Après 6 heures, la page devient "stale" mais continue d'être servie
Next.js régénère la page en arrière-plan
La nouvelle version remplace l'ancienne dans le cache
Exemple 2 : Server Actions avec Revalidation
Quand vous mettez à jour des données, vous pouvez revalider le cache :
'use server';
import { revalidateTag, revalidatePath } from 'next/cache';
import { updateAnnonceInBackend } from '@/features/annonce/api/update-annonce';
export async function updateAnnonce( reference: string, data: AnnonceData, ) {
await updateAnnonceInBackend(reference, data);
revalidateTag('annonces');
revalidatePath('/acheter');
revalidatePath(`/annonce/${reference}`);
}
export async function updateMandataire(slugMandataire: string) {
await updateMandataireInBackend(slugMandataire);
revalidateTag('mandataires');
revalidateTag('annonces');
revalidatePath(`/mandataire/${slugMandataire}`);
}
Comment ça marche :
revalidateTag('annonces') met à jour le manifeste avec le timestamp actuel
Toutes les entrées de cache avec le tag 'annonces' deviennent obsolètes
Les prochaines requêtes régénèrent les pages automatiquement
Le cache est mis à jour avec les nouvelles données
Exemple 3 : Appel API avec Cache
Voici comment une fonction de fetch utilise le cache :
import { fetchAndValidate } from '@/utils/fetch-and-validate';
import { annonceDetailSchema } from '@/features/annonce/schemas/annonce.schema';
import { API_ROUTES } from '@/constants/api-route.constants';
export async function fetchDetailAnnonce( ref: string, localisation: string, locale: Locale, ) {
const detailUrl = `${API_ROUTES.annonce.detail}/${ref}`;
const data = await fetchAndValidate(detailUrl, annonceDetailSchema);
return adaptAnnonceDetailFromDto(data);
}
Optimisations et Bonnes Pratiques
Logging avec Pino
Le cache handler utilise pino, un logger rapide et structuré. Configuration recommandée :
Développement :
PINO_LOG_LEVEL=debug
Production :
PINO_LOG_LEVEL=info
Types de logs émis :
🔧 Cache directory initialized : Initialisation du répertoire✅ Cache hit : Entrée trouvée et valide⚠️ Cache miss : Entrée non trouvée♻️ Cache entry is stale : Entrée obsolète📥 Set cached data : Données mises en cache🔄 Revalidating tags : Début de revalidation
Gestion de l'Espace Disque
Le cache peut grandir indéfiniment. Voici comment le gérer :
Surveillance :
du -sh .cache/
find .cache/ -type f | wc -l
find .cache/ -type f -exec ls -lh {} \; | sort -k5 -hr | head -10
Nettoyage automatique :
Créez une route API pour vider le cache :
import { NextResponse } from 'next/server';
import { promises as fs } from 'fs';
import path from 'path';
import { env } from '@/env/server';
import logger from '@/lib/logger/logger';
const CACHE_DIR = path.resolve('.cache');
export async function POST(request: Request) {
try {
const authHeader = request.headers.get('authorization');
const expectedSecret = env.CACHE_CLEAR_SECRET;
if (!expectedSecret || authHeader !== `Bearer ${expectedSecret}`) {
return NextResponse.json({ error: 'Unauthorized' }, { status: 401 });
}
await fs.rm(CACHE_DIR, { recursive: true, force: true });
await fs.mkdir(CACHE_DIR, { recursive: true });
logger.info({ message: '🧹 Cache vidé avec succès' });
return NextResponse.json({
success: true,
message: 'Cache cleared successfully',
});
} catch (error) {
logger.error({ message: 'Erreur lors du nettoyage du cache', error });
return NextResponse.json(
{ error: 'Failed to clear cache' },
{ status: 500 },
);
}
}
Cron job avec GitLab CI :
clear-cache:
stage: maintenance
image: curlimages/curl:latest
script:
- |
curl -X POST \
-H "Authorization: Bearer ${CACHE_CLEAR_SECRET}" \
"${NEXT_PUBLIC_URL}/api/cache/clear" \
-f
only:
- schedules
variables:
CACHE_CLEAR_SECRET: $CACHE_CLEAR_SECRET
NEXT_PUBLIC_URL: $NEXT_PUBLIC_URL
Configurez un schedule GitLab pour exécuter ce job quotidiennement à 00h00.
Monitoring et Alertes
Métriques à surveiller :
Taille du cache : Alerte si > 1 GB
Nombre de fichiers : Alerte si > 10 000
Taux de cache hit : Surveiller via les logs
Espace disque : Alerte si < 20% disponible
Exemple avec Datadog :
{
"requests": [
{
"q": "avg:kubernetes.ephemeral_storage.usage{kube_namespace:production} by {pod_name}",
"display_type": "line"
}
],
"title": "Espace disque utilisé par pod - Cache Next.js"
}
Comparaison des Solutions : Système de Fichiers vs Redis vs S3 + CloudFront
Vitesse
- Système de Fichiers : 🟡 Moyenne (5-50ms) - Lecture/écriture sur disque local
- Redis : 🟢 Rapide (< 10ms) - Accès réseau optimisé, en mémoire
- S3 + CloudFront : 🔴 Lente (50-200ms) - Latence réseau importante
Persistance
- Système de Fichiers : ✅ Native - Les fichiers sont persistants par nature
- Redis : ⚠️ Configurable - Nécessite configuration (AOF, RDB) pour la persistance
- S3 + CloudFront : ✅ Native - Stockage objet persistant
Partage
- Système de Fichiers : ✅ Volume partagé - Via PVC Kubernetes ou volume Docker
- Kubernetes : PVC avec ReadWriteMany pour partage multi-pods
- Docker Compose : Volume nommé partagé
- Redis : ✅ Natif - Partage automatique entre toutes les instances
- S3 + CloudFront : ✅ Global - Accessible depuis n'importe où dans le monde
Complexité
- Système de Fichiers : 🟢 Simple - Pas de service externe, code minimal
- Redis : 🟡 Moyenne - Nécessite un service Redis à gérer
- S3 + CloudFront : 🔴 Complexe - Configuration AWS, credentials, IAM, etc.
Coûts
- Système de Fichiers : 🟢 Gratuit - Utilise l'espace disque existant
- Redis : 🟡 Payant (hébergement) - Coût du service Redis (managed ou self-hosted)
- S3 + CloudFront : 🔴 Payant (stockage + requêtes) - Coûts de stockage et de transfert
Scalabilité
- Système de Fichiers : 🟡 Limitée - Performance dégrade avec beaucoup de fichiers (> 10 000)
- Redis : 🟢 Excellente - Conçu pour de gros volumes, clustering possible
- S3 + CloudFront : 🟢 Excellente - Scalabilité illimitée, distribution globale
Visibilité
- Système de Fichiers : 🟢 Fichiers inspectables - Accès direct aux fichiers JSON
- Redis : 🟡 Via CLI/UI - Nécessite redis-cli ou outils de monitoring
- S3 + CloudFront : 🔴 Via console AWS - Interface web uniquement
Quand Utiliser Chaque Solution ?
Système de fichiers (notre implémentation) :
- ✅ Volume modéré (< 10 000 entrées)
- ✅ Self-hosting simple
- ✅ Budget limité
- ✅ Besoin de simplicité
Redis :
- ✅ Gros volumes (> 50 000 entrées)
- ✅ Multi-instances avec partage
- ✅ Besoin de performance
- ✅ Budget pour infrastructure
S3 + CloudFront :
- ✅ Distribution globale
- ✅ Très gros volumes
- ✅ Besoin de CDN intégré
- ✅ Budget important
Migration vers Redis (si nécessaire)
Si vous dépassez les limites du système de fichiers, voici un exemple de migration vers Redis :
import { createClient } from 'redis';
const redisClient = createClient({
url: process.env.REDIS_URL,
});
await redisClient.connect();
class CacheHandler {
async get(key) {
const data = await redisClient.get(key);
if (!data) return null;
return JSON.parse(data);
}
async set(key, data, ctx = {}) {
const entry = {
value: data,
lastModified: Date.now(),
tags: ctx.tags || [],
};
await redisClient.setEx(key, 86400, JSON.stringify(entry));
}
async revalidateTag(tags) {
}
}
Benchmarks Estimés
Système de fichiers :
- Cache hit : 5-20ms (lecture disque)
- Cache miss : 50-200ms (génération + écriture)
- Revalidation : < 10ms (mise à jour manifeste)
Capacité recommandée :
- Jusqu'à 10 000 entrées : Performance acceptable
- 10 000 - 50 000 entrées : Ralentissements possibles
- > 50 000 entrées : Considérer Redis
Optimisations Possibles
Sous-dossiers : Organiser les fichiers par hash pour éviter trop de fichiers dans un seul dossier
Compression : Compresser les entrées volumineuses
Index en mémoire : Garder un index des clés en mémoire pour des recherches rapides
LRU manuel : Implémenter un LRU pour supprimer les anciennes entrées
Dépannage et Debugging
Problèmes Courants
1. Le cache ne fonctionne pas
cat next.config.ts | grep cacheHandler
ls -la .cache/
PINO_LOG_LEVEL=debug npm run dev
2. Le cache est trop volumineux
du -sh .cache/
find .cache/ -type f -exec ls -lh {} \; | sort -k5 -hr | head -10
rm -rf .cache/*
3. Les revalidations ne fonctionnent pas
cat .cache/tags-manifest.json | jq
Commandes utiles
watch -n 1 'du -sh .cache/ && find .cache/ -type f | wc -l'
npm run dev 2>&1 | grep -i cache
cat .cache/$(echo -n "/fr/annonce/paris/propriete/ABC123" | base64).json | jq
df -h
FAQ : Questions Fréquentes
Réponse : Oui, légèrement. Le cache sur disque est plus lent que le cache en mémoire (5-50ms vs < 1ms), mais les bénéfices (persistance, partage) compensent souvent cette perte. Pour des applications très performantes, considérez Redis.
2. Puis-je utiliser Redis au lieu du système de fichiers ?
Réponse : Absolument ! L'interface du cache handler est la même. Il suffit de modifier les méthodes get() et set() pour utiliser Redis au lieu du système de fichiers. Redis offre de meilleures performances et un partage natif entre instances.
Réponse : Deux options principales :
- Volume partagé : Utilisez un PersistentVolumeClaim (PVC) monté sur tous les pods
- Redis : Utilisez un service Redis partagé (plus performant et scalable)
4. Le cache fonctionne-t-il avec ISR (Incremental Static Regeneration) ?
Réponse : Oui, c'est exactement pour ça ! Le cache handler est utilisé par Next.js pour stocker les pages ISR. La revalidation fonctionne via le système de tags.
5. Dois-je nettoyer le cache régulièrement ?
Réponse : Oui, surtout si vous avez beaucoup de pages. Le cache peut grandir indéfiniment. Configurez un cron job pour nettoyer quotidiennement ou implémentez un LRU/TTL dans le cache handler.
6. Puis-je mettre le cache sur S3 pour une meilleure scalabilité ?
Réponse : Techniquement oui, mais ce n'est pas recommandé. S3 ajoute de la latence (50-200ms) sans bénéfice réel pour le cache handler (qui est côté serveur). Utilisez S3 pour servir les pages ISR via un CDN, pas pour le cache handler.
Réponse :
Activez les logs debug : PINO_LOG_LEVEL=debug
Inspectez le répertoire .cache/
Vérifiez le manifeste des tags : cat .cache/tags-manifest.json
Surveillez les logs en temps réel : npm run dev | grep cache
8. Le cache handler fonctionne-t-il en développement ?
Réponse : Oui, mais en développement Next.js utilise souvent le mode "dev" qui peut bypasser le cache. Pour tester, utilisez npm run build && npm run start pour simuler la production.
9. Puis-je exclure certaines routes du cache ?
Réponse : Oui, modifiez la constante EXCLUDED_ROUTES dans cache-handler.mjs :
const EXCLUDED_ROUTES = [
'/robots.txt',
'/sitemap.xml',
'/api/webhooks', // Routes dynamiques
];
10. Quelle est la différence entre
Réponse : En réalité, revalidatePath() appelle revalidateTag() en interne. Les chemins de routes sont des tags dans Next.js. Utilisez revalidateTag() pour des tags personnalisés et revalidatePath() pour des chemins spécifiques.
Conclusion
Créer un cache handler personnalisé pour Next.js vous donne un contrôle total sur votre système de cache, essentiel pour le self-hosting. Dans ce guide, nous avons couvert :
✅ L'architecture complète d'un cache handler avec stockage persistant
✅ Une implémentation pas à pas avec code complet et fonctionnel
✅ Des exemples pratiques basés sur un cas d'usage réel (annonces immobilières)
✅ Les optimisations et bonnes pratiques pour la production
✅ La comparaison des solutions (fichiers, Redis, S3)
✅ Le monitoring et le dépannage pour maintenir votre cache
Prochaines Étapes
Implémentez le cache handler dans votre projet Next.js en suivant ce guide
Configurez le monitoring pour surveiller la taille et les performances (Datadog, Prometheus, etc.)
Testez en production avec un volume réaliste de trafic pour valider les performances
Optimisez selon vos besoins spécifiques (LRU, TTL, compression, migration vers Redis si nécessaire)